A tecnologia além de proporcionar inúmeras vantagens e inovações, também é um meio de coletar e armazenar dados que colaboram na tomada de decisões e na solução de problemas de diversas áreas. O grande desafio é encontrar informações relevantes diante de imensos volumes de dados gerados diariamente pela sociedade. Desta maneira, como podemos utilizar dados brutos para diversos tipos de análises e obter insights para tomar decisões e resolver problemas? Aplicando Mineração de Dados!
O que é Mineração de Dados?
Mineração de dados é um processo para coletar e explorar grandes volumes de dados com a finalidade de encontrar padrões, relações e anomalias para obter insights valiosos, entender características do passado e predizer características para o futuro.
Como é o processo de Mineração de Dados?
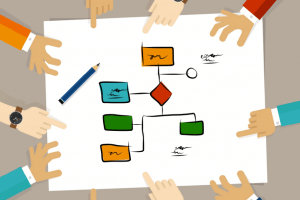
A Mineração de Dados consiste em etapas que não possuem uma sequência obrigatória. Na imagem abaixo, podemos observar seu ciclo de vida e as relações mais frequentes entre as etapas.

Não existe uma solução universal que possui a melhor performance e os melhores resultados. As escolhas e resultados em cada etapa dependem do seu objetivo em executar o processo de Mineração de Dados.
-
Entendimento de Negócio (Business Understanding)
A primeira parte desta etapa é compreender o negócio por completo e, se necessário, identificar pessoas especialistas que possam colaborar com a compreensão das regras e necessidades do negócio. Em seguida, é importante responder duas perguntas que contribuirão para as etapas futuras:
1.1. Qual é o objetivo da Mineração de Dados?
Identificar um objetivo colabora com a consolidação das ideias e com o direcionamento da Mineração de Dados. Para exemplificar, alguns possíveis objetivos são: melhorar um processo já existente, melhorar métricas e indicadores, desenvolver uma inovação, oferecer um serviço, entre outros.
1.2. Qual é o problema que quero resolver ou qual é a pergunta que quero responder com a Mineração de Dados?
Definir detalhadamente um problema é essencial não apenas para um bom resultado, mas também para a escolha das técnicas que serão utilizadas nas próximas etapas.
Para definir um bom problema ou uma boa pergunta é necessário realizar uma análise crítica do negócio e identificar os problemas que, quando resolvidos, agreguem um bom valor. Em uma empresa, por exemplo, o problema pode ser definido à partir da observação dos gargalos em fluxos de trabalho, tarefas que podem ser otimizadas para economizar tempo e dinheiro, entre outros.
-
Entendimento e Preparação dos dados (Data Understanding & Data Preparation)
Para entender a importância desta etapa, podemos citar a famosa expressão de George Fuechsel, “Garbage in, garbage out” (em português, “Lixo entra, lixo sai”) que faz referência à qualidade dos dados. O resultado da Mineração de Dados depende diretamente de bons dados, ou seja, dados representativos, válidos e sem viés. A qualidade e quantidade dos dados dependem da complexidade do problema que queremos resolver.
2.1. Coleta dos dados
Os dados que precisamos podem estar em diferentes fontes, tais como banco de dados, páginas web, redes sociais dentre outros. Desta maneira, o ideal é selecionar os dados relevantes considerando a privacidade e a quantidade dos dados, consolidá-los e armazená-los em uma base de dados única.
Nesta etapa é indispensável verificar se os dados possuem todos os atributos necessários para solucionar o problema definido. Para isso, podemos tentar responder a seguinte pergunta: é possível resolver o problema com os dados coletados? Se os dados disponíveis não resolvem o problema definido, a decisão mais comum é coletar mais dados e, em alguns casos, a decisão mais viável é adaptar o problema definido para que seja respondido por meio dos dados disponíveis.
2.2. Preparação dos Dados
A preparação dos dados é a etapa que exige maior esforço e dedicação de todo o processo. Esta etapa consiste na limpeza, transformação e formatação dos dados e cada atividade depende diretamente dos dados. Algumas atividades frequentes na preparação dos dados são:
Remover atributos irrelevantes: atributos que não possuem informação útil. Exemplos: ID de uma pessoa; atributo com valor constante.
- Tratar valores faltantes e/ou inválidos: remover ou preencher com novos valores.
- Tratar anomalias (outliers): Outliers são os dados que se diferenciam extremamente de todos os outros, ou seja, estão fora do intervalo esperado, no sentido estatístico, dos dados. Se os outliers influenciam negativamente o resultado da análise, podemos removê-los e se os outliers possuem o comportamento que queremos analisar, podemos mantê-los na base de dados.
- Transformar atributos nominais em numéricos: os algoritmos de modelagem atuam melhor com números. Exemplo: transformar sim ou não em 1 ou 0.
- Inserir atributos (feature engineering): criar novos atributos que contribuem para melhorar a performance e o resultado da modelagem. Exemplo: Utilizar o atributo gênero, peso, idade e altura para criar o novo atributo IMC.
- Transformar a escala dos dados: transformar os atributos na mesma escala evita que a modelagem seja influenciada pelos atributos de maior ordem de grandeza. Exemplo: Reescalar os dados para que todos os valores estejam no intervalo entre 0 e 1.
Há diversas maneiras para executar cada uma dessas atividades e, mais uma vez, depende dos dados disponíveis e do problema definido.
2.3. Análise Exploratória dos Dados (Exploratory Data Analysis – EDA)
A Análise Exploratória de Dados é uma abordagem para entender profundamente os dados, verificar se os dados e o problema definido fazem sentido, além de obter bons insights.
Nesta etapa, podemos identificar as principais características, tendências, relações, padrões e comportamento dos dados por meio de visualizações gráficas (barras, linhas, correlação, dispersão entre outros) e com tabelas. Após a Análise Exploratória de Dados é possível compreender melhor os dados e, se necessário, revisitar a etapa de preparação dos dados com novas abordagens.
-
Modelagem
A modelagem consiste em aplicar técnicas de Inteligência Artificial nos dados preparados para identificar correlações, padrões e tendências que contribuam para a solução desejada.
O primeiro passo é identificar qual é a melhor abordagem para o problema. Existem diversas abordagens e uma das mais utilizadas é de Aprendizado de Máquina (Machine Learning), composta por algoritmos que, a partir de um grande volume de dados, podem aprender sozinhos a encontrar um resultado. Tipos mais utilizados de Aprendizado de Máquina:
Aprendizado supervisionado
O modelo possui uma referência de resultados pré-definidos e aprende a fazer predições “supervisionando” esses valores, isto é, o modelo aprende o padrão dos resultados que já conhece e faz a predição dos novos valores. Existem dois tipos de aprendizado supervisionado:
– Regressão: o modelo aprende como um atributo se comporta em relação à outro atributo e é capaz de predizer comportamentos futuros. Este modelo é utilizado em problemas com um resultado numérico (contínuo). Exemplo: prever o preço de venda de uma casa baseado em seu tamanho, considerando os dados já conhecidos de preços e tamanhos de outras casas.
– Classificação: o modelo supervisiona a classificação de dados já conhecidos e é capaz de predizer a classificação de novos dados. Este modelo é utilizado em problemas com um resultado categórico (binário: sim (1) ou não (0), níveis: baixo, médio, alto entre outros). Exemplo: prever se uma nova música se tornará um grande sucesso (sim ou não) comparando as características da nova música com as características das músicas que já são sucesso e das músicas que não são sucesso.
Aprendizado não supervisionado
Não existe resultados pré-definidos como referência para o aprendizado do modelo. Há dois tipos de aprendizado não supervisionado:
– Agrupamento: o modelo calcula as semelhanças e diferenças entre os dados e aprende sozinho o melhor modo possível de agrupá-los de maneira que os dados semelhantes pertençam ao mesmo grupo. Exemplo: analisar um conjunto de dados de plantas e agrupá-las por tipos (plantas para jardim, plantas carnívoras ou plantas medicinais).
– Associação: o modelo aprende um padrão de regras e é capaz de associar comportamentos. Exemplo: recomendar um filme para o usuário baseado nas características dos últimos filmes que o usuário assistiu.
Aprendizado por reforço
O modelo aprende a atingir o resultado esperado por tentativa e erro, isto é, o modelo enfrenta uma situação e tenta descobrir qual é a melhor ação no momento e recebe recompensas ou penalidades por cada ação executada. O objetivo do modelo é atingir o resultado esperado maximizando a recompensa total
Este tipo de aprendizado é utilizado com frequência em jogos, nos quais uma Inteligência Artificial (modelo) aprende e é capaz decidir sozinha suas ações, a partir das recompensas e penalidades, para concluir todas as fases.
Para exemplificar, podemos assistir o seguinte vídeo que explica como uma Inteligência Artificial aprende a vencer o jogo do Dinossauro da página do Google “Sem Internet”:
Após escolher a melhor abordagem, é necessário escolher o algoritmo mais adequado e esta escolha depende dos dados disponíveis e do problema definido. Diante de tantas opções, é essencial realizar uma validação e, baseado métricas, decidir qual é o melhor algoritmo para resolver nosso problema.
-
Avaliação
As técnicas e métricas de validação também são inúmeras e dependem da abordagem escolhida na modelagem. Uma das técnicas mais comuns para validação é selecionar uma parte da base de dados e usá-la como teste e assim comparar o resultado que o algoritmo apresentou (resultado estimado) com o resultado real (resultado dos dados de teste).
A métrica mais utilizada é a acurácia que representa o quão próximo o resultado estimado está do resultado real, isto é, quanto maior é a porcentagem da acurácia, melhor e mais confiável é a nossa modelagem. Além disso, é importante avaliar se os resultados estão de acordo com o problema definido inicialmente.
-
Aplicação (Deployment)
A última etapa é a entrega do estudo realizado no processo de Mineração de Dados que pode ser desde um relatório com os resultados obtidos até instruções para executar o processo de Mineração de Dados com novos dados diversas vezes.
-
Principais vantagens da Mineração de Dados
Com a aplicação da mineração de dados podemos transformar dados brutos em informações e insights relevantes, analisar os dados de forma eficiente, predizer comportamentos e auxiliar na solução de problemas de diversas áreas tanto no mercado de trabalho, possibilitando uma vantagem competitiva da empresa, quanto em pesquisas, resultando em grandes avanços nos estudos científicos.
-
Principais aplicações de Mineração de Dados
- Marketing: Definição de estratégias de campanhas para prever quais clientes comprarão um novo produto ou serviço, análise de padrões de comportamento dos consumidores e segmentação dos clientes.
- Finanças: Diversas análises de padrões para entender e prever comportamentos, tais como transações fraudulentas, análise de crédito e de limite de cartões e análise de financiamentos e investimentos.
- Saúde: Reconhecimento de imagens radiológicas para identificar e classificar doenças, análise de sintomas, tratamentos e efeitos colaterais, além de contribuições com informações e insights para avanços em pesquisas da área.
- Games: Investigação de problemas como o baixo número e/ou evasão de jogadores, análise de métricas para aperfeiçoamento de jogabilidade tal como nível de dificuldade das fases e compreensão de pontos positivos e negativos para o sucesso do jogo.
-
Considerações finais
A Mineração de Dados pode ser aplicada em diversas áreas e, provavelmente, pode contribuir com os desafios que você enfrenta na sua empresa ou na sua pesquisa. Os dados estão em todos os lugares e com criatividade, pensamento lógico e estratégico você pode identificar os principais problemas e os dados disponíveis que podem colaborar com melhores insights e soluções para estes desafios.
Você também pode gostar de ler: